
Boxplots geben einen schnellen Überblick über Verteilungen. Wie kann man sie informativer gestalten als das Standard-Boxplot? Hier geht es um Ideen mit ggplot2 sowie einigen Erweiterungspaketen.
Zum Einstieg in ggplot2 siehe die folgenden Beiträge:
- ggplot2: Einführung in die drei Basisschichten – Daten, Ästhetiken, Geometrien
- ggplot2: Die vier fortgeschrittenen Schichten
- ggplot2 leicht gemacht: Grafiken per Maus dank esquisse!
Das folgende Video ist mein erstes, das auf einem Storyboard basiert – umgesetzt mit dem flexdashboard-Paket, das eine Erweiterung des R Markdown-Formats darstellt. Schreibt in den Kommentaren, ob Euch dieses Format für Videos gefällt und welche der folgenden Ideen ihr nutzt oder nutzen wollt!
Das Dashboard mit dem eingebetteten R-Code findet Ihr hier (mit englischem Text).
TL; DR
Für Eilige (TL; DR = too long, didn’t read): Folgende Ideen werden in diesem Artikel und im Video präsentiert:
- Fallzahlen visuell berücksichtigen
- Fallzahlen numerisch angeben (EnvStats)
- Zusammenfassende Statistiken per Mouse-Over einblenden (plotly)
- Ausreißer beschriften
- Individuelle Datenpunkte mit darstellen
- Informationen zu einer weiteren Variable mit darstellen
- Mittelwerte zusätzlich zu Medianen anzeigen
- Statistische Gruppenvergleiche berechnen und publikationsfähig einzeichnen (ggstatsplot)
- Bilder zur Achsenbeschriftung nutzen (ggtext)
Daten: Musikcharts, 2000 bis 2020
Die Daten stammen von der Seite chart2000.com, der Datensatz von dort heißt chart2000-songyear-0-3-0062.csv. Da sich auf chart2000.com die Versionsnummer ändern dürfte, findet Ihr die hier verwendeten Daten auch auf meinem github-Profil. Die Daten enthalten die Top 100 Songs für jedes Jahr von 2000 bis 2020.
Ich habe mich auf die fünf erfolgreichsten Künstler / Bands beschränkt im Sinne des Gesamtscores, der hier als indicative revenue bezeichnet wird. Er stellt einen Versuch dar, den Erlös eines Songs abzubilden, und berücksichtigt dazu Währungseffekte und Inflation. Eine Einheit entspricht 1000 US-Dollar. Dazu ist die jeweilige Chartposition in verschiedenen Musikmärkten verzeichnet: USA, Vereinigtes Königreich, Deutschland, Frankreich, Kanada, Australien.
Das Dashboard mit Daten, Diagrammen, Erläuterungen und R-Code findet Ihr hier.
# Pakete laden
library(knitr)
library(kableExtra)
library(flexdashboard)
library(tidyverse)
library(ggthemes)
library(DT)
library(plotly)
library(EnvStats)
library(ggstatsplot)
library(ggtext)
# Daten laden
all_songs <- read_csv(file = "chart2000-songyear-0-3-0062.csv",
na = c("", "-"))
# Attribute entfernen
attr(all_songs, "spec") <- NULL
# Top 5 Künstler nach indicative revenue bestimmen (Gesamtsumme)
top_artists <- all_songs %>%
group_by(artist) %>%
summarise(total_score = sum(indicativerevenue)) %>%
arrange(desc(total_score)) %>%
head(n = 5) %>%
pull(artist)
songs <- all_songs %>%
filter(artist %in% top_artists) %>%
mutate(artist = fct_infreq(artist),
indicativerevenue = round(indicativerevenue))
# Interaktive Tabelle (funktioniert nur in Markdown-Formaten mit HTML, nicht in blanken R-Skripten)
datatable(songs, filter = "top")
Boxplot der Top 5 Künstler / Bands
Hier das erste Boxplot:

Das erste Boxplot zeigt die Erlöse der Top 5 Künstler / Bands. Ich habe das theme_solarized() aus dem ggthemes-Paket von Jeffrey B. Arnold verwendet, die Künstler nach Anzahl der Songs in den Top 100 sortiert, die y-Achsen-Beschriftung um 90 Grad gedreht, die Schriftgröße erhöht, die Markierungs-Striche an der x-Achse sowie die vertikalen Rasterlinien entfernt.
# Theme-Einstellungen: Müssen so nicht bei jedem Diagramm neu angegeben werden
theme_set(theme_solarized(base_size = 15))
theme_update(axis.text.x = element_text(angle = 90),
axis.ticks.x = element_blank(),
panel.grid.major.x = element_blank())
# Erstes Diagramm
ggplot(songs, aes(x = artist, y = indicativerevenue)) +
geom_boxplot() +
labs(x = "", y = "Indicative Revenue",
title = "Indicative Revenue by Artist",
subtitle = "Artists sorted by number of songs in Top 100 per year",
caption = "Source: Chart2000.com, Songs of the year, Version 0-3-0062")
Idee 1: Fallzahlen visuell berücksichtigen
Die erste Verbesserung ist recht simpel: Da Fallzahlen zur Beurteilung von Verteilungen eine zentrale Rolle spielen, sollten sie erkennbar sein. Dazu bietet sich der Parameter varwidth = TRUE in geom_boxplot() an, der die Breite der Boxen von der Fallzahl abhängig macht. Hier sind die Auswirkungen nicht dramatisch, da die Fallzahlen sich in ähnlichen Größenordnungen bewegen.

ggplot(songs, aes(x = artist, y = indicativerevenue)) +
geom_boxplot(varwidth = TRUE) +
labs(x = "", y = "Indicative Revenue",
title = "Indicative Revenue by Artist",
subtitle = "Artists sorted by number of songs in Top 100 per year",
caption = "Source: Chart2000.com, Songs of the year, Version 0-3-0062")
Idee 2: Fallzahlen numerisch angeben
Noch besser ist es, die Fallzahlen auch numerisch anzugeben. Wir könnten sie selbst berechnen und mit geom_text() oder geom_label() einblenden. Einfacher ist es jedoch, die Funktion stat_n_text() aus dem EnvStats-Paket von Steven Millard und Alexander Kowarik zu nutzen:

ggplot(songs, aes(x = artist, y = indicativerevenue)) +
geom_boxplot(varwidth = TRUE) +
labs(x = "", y = "Indicative Revenue",
title = "Indicative Revenue by Artist",
subtitle = "Artists sorted by number of songs in Top 100 per year",
caption = "Source: Chart2000.com, Songs of the year, Version 0-3-0062") +
stat_n_text(y.pos = 900)
Idee 3: Interaktives Diagramm, Statistische Kennzahlen per Mouse-Over
Bei der dritten Option für ein informativeres Diagramm geht es um die Kennzahlen, die im Boxplot dargestellt werden: Minimum und Maximum, unteres und oberes Quartil, Median, ggf. die Antennen (whisker / fence). plotly (Carson Sievert) ermöglicht dank Javascript interaktives Einblenden von Zusatzinformationen entsprechend der Position des Mauszeigers.

Hier habe ich plotly-Code geschrieben anstelle der etwas bekannteren Methode, zunächst ein ggplot2-Diagramm zu erstellen, dieses als Objekt zu speichern und das dann der ggplotly()-Funktion zu übergeben. Hinweis: plotly berechnet die Kennzahlen etwas anders als ggplot2; Ausreißer sind anders definiert.
songs %>%
plot_ly(x = ~artist, y = ~indicativerevenue,
type = "box")
Idee 4: Ausreißer beschriften
Ausreißern kommt mitunter eine besondere Bedeutung zu. Wie praktisch, wenn man sie nicht nur als Punkte einzeichnet, sondern auch beschriftet. Das tun wir hier mit einer benutzerdefinierten Funktion.

Die Funktion zur Ermittlung der Ausreißer habe ich auf stackoverflow gefunden (Antwort von JasonAizkalns). Sie gibt für Ausreißer den Song zurück, ansonsten den Fehlwert NA. Die damit berechnete Variable wird geom_text() übergeben. Außerdem habe ich hier die Gruppen (Bands / Künstler) nach Farben unterschieden und die Legende für die Farben unterdrückt – die Bands sind ohnehin klar erkennbar.
is_outlier <- function(x) {
return(x < quantile(x, 0.25) - 1.5 * IQR(x) | x > quantile(x, 0.75) + 1.5 * IQR(x))
}
songs %>%
group_by(artist) %>%
mutate(outlier = ifelse(is_outlier(indicativerevenue), song, NA)) %>%
ggplot(aes(x = artist, y = indicativerevenue, color = artist)) +
geom_boxplot(varwidth = TRUE) +
geom_text(aes(label = outlier), na.rm = TRUE, nudge_y = 1500) +
labs(x = "", y = "Indicative Revenue",
title = "Indicative Revenue by Artist",
subtitle = "Artists sorted by number of songs in Top 100 per year",
caption = "Source: Chart2000.com, Songs of the year, Version 0-3-0062") +
scale_color_discrete(guide = NULL)
Idee 5: Einzelne Datenpunkte mit darstellen
Es ist möglich, für unterschiedliche Verteilungen dasselbe Boxplot zu erhalten – etwa für normalverteilte Daten (viele Daten in der Nähe des Mittelwertes) und u-förmig verteilte Daten (zwei „Spitzen“, unterhalb und oberhalb des Mittelwerts, mit wenigen Datenpunkten dazwischen). Daher kann es sinnvoll sein, alle Datenpunkte darzustellen, um einen genaueren Eindruck von den jeweiligen Verteilungen zu liefern. Dieses Vorgehen ist inspiriert von Edward Tufte und seiner Idee, Mikro- und Makro-Ebene zu verbinden. Siehe zum Beispiel sein empfehlenswertes Werk Envisioning Information.

Hier gibt es eine Falle: Wenn man nicht aufpasst, stellt sowohl geom_boxplot() als auch geom_jitter() die Ausreißer dar, sodass sie doppelt erscheinen. (Darauf zu kommen hat mich schon mal viel Zeit gekostet!) Zur Abhilfe unterdrücke ich die Ausreißer im Boxplot mit outlier.color = NA. geom_jitter() sorgt für eine Zufallsverschiebung der Punkte – hier nur in x-Richtung, sodass sie nicht alle exakt übereinander dargestellt werden. Zudem verwende ich Transparenz (engl. opacity, in ggplot2 alpha), sodass man erkennen kann, wo sich Punkte überlagern.
ggplot(songs, aes(x = artist, y = indicativerevenue, color = artist)) +
geom_boxplot(varwidth = TRUE, outlier.color = NA) +
geom_jitter(alpha = 0.6, width = 0.2, height = 0) +
labs(x = "", y = "Indicative Revenue",
title = "Indicative Revenue by Artist",
subtitle = "Artists sorted by number of songs in Top 100 per year",
caption = "Source: Chart2000.com, Songs of the year, Version 0-3-0062") +
scale_color_discrete(guide = NULL) +
stat_n_text(y.pos = 900)
Idee 6: Informationen zu weiterer Variable darstellen
Wenn man schon einzelne Datenpunkte abbildet, kann man auch weitere Informationen mit codieren. Hier stelle ich mit dar, ob ein Song wenigstens in einem Land Platz 1 der Jahrescharts erreichte. Um die optische Unterscheidung möglichst deutlich hervorzuheben, nutze ich dafür sowohl Farbe als auch Form und kombiniere diese Infos in einer gemeinsamen Legende.
Man könnte auch zwei oder mehr Variablen zusätzlich codieren – hier gilt es sorgfältig abzuwägen, ob das noch lesbar und sinnvoll ist und ob die Betrachter so viel Zeit, Mühe und Verständnis aufbringen (wollen), diese Informationen abzulesen.

Interessant, dass die beiden erfolgreichsten Songs von Ed Sheeran sowie die Top Songs der Black Eyed Peas Nummer 1-Songs in den Jahrescharts waren, dass dies jedoch nicht für die Topsongs von Maroon 5, Pink und Rihanna gilt.
songs %>%
rowwise() %>%
mutate(no1 = any(c_across(us:au) == 1, na.rm = TRUE)) %>%
ggplot(aes(x = artist, y = indicativerevenue)) +
geom_boxplot(varwidth = TRUE, outlier.color = NA) +
geom_jitter(alpha = 0.6, width = 0.2, height = 0,
aes(shape = no1, color = no1)) +
labs(x = "", y = "Indicative Revenue",
title = "Indicative Revenue by Artist",
subtitle = "Artists sorted by number of songs in Top 100 per year",
caption = "Source: Chart2000.com, Songs of the year, Version 0-3-0062") +
scale_color_brewer(palette = "Dark2",
name = "No. 1\n(Any Country)?") +
scale_shape_discrete(name = "No. 1\n(Any Country)?") +
stat_n_text(y.pos = 900)
Der geneigte Leser beachte die Verwendung von dplyr::rowwise() und mutate(any(c_across(…))) für die zeilenweise Bestimmung, ob ein Song Nummer 1-Status in den Jahrescharts erlangte. geom_jitter() erhält zusätzliche Ästhetiken (shape und color). Damit die Farb- und Form-Infos in einer gemeinsamen Legende und nicht in zwei separaten Legenden dargestellt werden, müssen sie 1. auf die gleiche Variable zugreifen und 2. den gleichen Legenden-Titel (name) tragen.
Idee 7: Mittelwerte einzeichnen zum Vergleich mit den Medianen
Der Vergleich zwischen Mittelwert und Median kann interessante Erkenntnisse über Verteilungen liefern. Während sie bei Normalverteilungen zusammenfallen, können sie insbesondere bei starken Ausreißern deutlich auseinanderfallen. (Vergleiche den Beitrag Mittelwert oder Median? Beschreibung der Einkommensverteilung.)
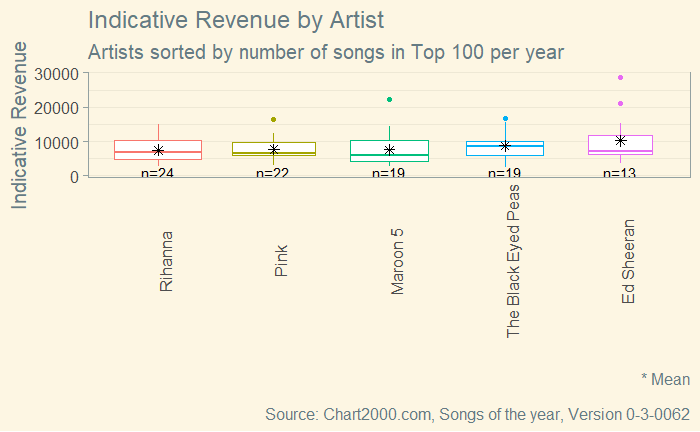
Hier verzichte ich auf die Darstellung der einzelnen Datenpunkte, um das Diagramm nicht zu überladen.
Bei Ed Sheeran und Maroon 5 „ziehen“ die Ausreißer den Mittelwert gegenüber dem Median nach oben, was bei Rihanna und den Black Eyed Peas nicht der Fall ist.
ggplot(songs, aes(x = artist, y = indicativerevenue, color = artist)) +
geom_boxplot(varwidth = TRUE) +
# geom_jitter(alpha = 0.6, width = 0.2, height = 0) +
stat_summary(fun = "mean", color = "black", shape = 8) +
labs(x = "", y = "Indicative Revenue",
title = "Indicative Revenue by Artist",
subtitle = "Artists sorted by number of songs in Top 100 per year",
caption = "* Mean\n\nSource: Chart2000.com, Songs of the year, Version 0-3-0062") +
scale_color_discrete(guide = NULL) +
stat_n_text(y.pos = 900)
Idee 8: Statistische Tests für Gruppenvergleiche berechnen und einzeichnen
Vor allem bei wissenschaftlichen Publikationen kann es hilfreich sein, statistische Gruppenvergleiche zu berechnen und publikationsfähig einzuzeichnen. Glücklicher Weise gibt es auch dafür ein R-Paket: ggstatsplot von Indrajeet Patil. Es ist sehr leistungsfähig und flexibel, gut auf ggplot2 abgestimmt, und sehr gut dokumentiert: Siehe help(package = “ggstatsplot”).

songs2 <- all_songs %>%
filter(artist %in% c("Ed Sheeran", "Justin Timberlake", "Miley Cyrus"))
ggstatsplot::ggbetweenstats(
data = songs2,
x = artist, xlab = "",
y = indicativerevenue,
ylab = "Indicative Revenue",
plot.type = "box",
type = "p",
conf.level = 0.95,
title = "Indicative Revenue by Artist"
)
Hier habe ich mich für die interessantere Variante mit drei Künstlern entschieden, bei der ein Gruppenvergleich signifikant ausfällt: Der zwischen Justin Timberlake und Miley Cyrus. Bei der sonst verwendeten Datenbasis mit den fünf Künstlern / Bands fällt kein Gruppenvergleich signifikant aus. Das alpha-Niveau wird anhand der Anzahl der Einzelvergleiche korrigiert (Holm). Bei einer Reihe von t-Tests ohne entsprechende Korrektur tritt die sog. Alpha-Fehler-Kumulierung auf (siehe Beitrag: Signifikant: Gummibärchen verursachen Akne). Vereinfacht ausgerückt: Wenn ich nur lange genug teste, wird schon mal was Signifikantes dabei sein, auch wenn es in der Grundgesamtheit keine Zusammenhänge / Unterschiede gibt.
Idee 9: Bilder als Achsenbeschriftungen
Wenn wir hier schon mit Stars der Musikszene zu tun haben – wäre es nicht ansprechender, Bilder anstatt langweiliger Text-Beschriftungen zu zeigen? Das geht mit dem ggtext-Paket von Claus Wilke.

Den Code zeige ich hier als Bild, da die HTML-Tags sonst von WordPress interpretiert werden und es versucht, im R-Code die Bilder einzubetten. Die Bilder habe ich vorab heruntergeladen und lokal gespeichert. ggtext erlaubt auch das Herunterladen live im ggplot-Aufruf, das klappt jedoch auf Windows nicht zuverlässig.

Beachtenswert die letzte Code-Zeile. ggtext::element_markdown() erlaubt Markdown-Formatierungen. Im Vektor labels sind die Künstler durch die Sterne zur Fettschrift gekennzeichnet. In der Zeile scale_x_discrete() wird auf die labels verwiesen.
Ich hoffe, es waren nützliche Infos für alle Leser dabei! Freue mich über Feedback. Viel Erfolg für Eure Visualisierungen! Gern zeige ich bei einem Workshop (gern auch per Video) Tricks zur Datenvisualisierung sowie zur Erstellung von Berichten, Präsentationen und Dashboards mit R.
Literaturtipps:
ggplot2: Elegant Graphics for Data Analysis (Use R!) – Hadley Wickham
R für Data Science: Daten importieren, bereinigen, umformen, modellieren und visualisieren
Interactive Web-Based Data Visualization with R, plotly, and shiny: Carson Sievert
2 Gedanken zu „Datenvisualisierung: Informative Boxplots in R (ggplot2 und mehr)“